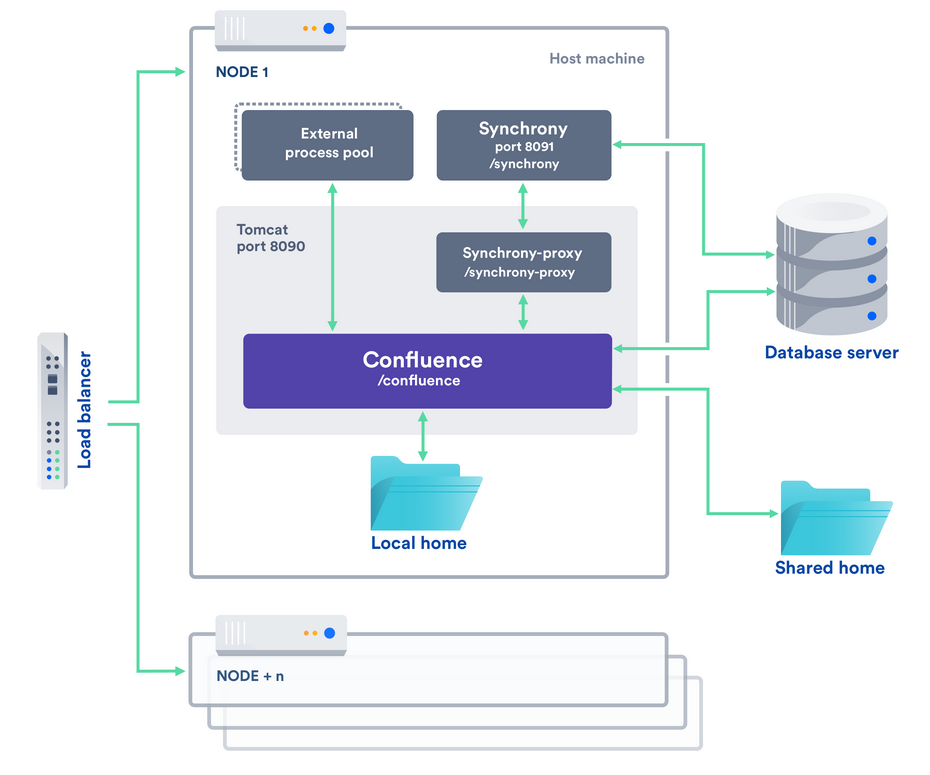
Confluence Data Center允许我们类似下图的集群中设置Confluence,其中包括:
- 运行Confluence应用程序的多个服务器节点和其他必需组件。
- 存储附件和其他共享文件的共享文件系统。
- 所有节点读取和写入的数据库。
- 负载平衡器将请求均匀地定向到每个节点。
所有Confluence节点都处于活动状态,并处理请求。用户将为所有请求访问同一Confluence节点,直到会话超时、注销或从集群中删除节点。
许可
数据中心许可证基于集群中的用户数,而不是节点数。我们可以在许可证页面中监视可用的许可证数量。
如果我们想自动化这个过程(例如在接近完全分配时发送警报),可以使用调用RESTAPI。
文件目录
Confluence有一个本地文件目录和共享文件目录的概念。
每个Confluence节点都有一个本地主页,其中包含日志、缓存、Lucene索引和配置文件。其他所有内容都存储在共享文件目录中,集群中的每个Confluence节点都可以访问该共享文件目录 。Marketplace应用程序可以根据应用程序的需要选择是在本地还是共享文件目录中存储数据。
以下是在本地文件目录和共享文件目录中存放内容的目录说明:
| 本地文件目录 | 共享文件目录 |
|---|---|
|
|
缓存
Confluence使用分布式缓存,该缓存使用Hazelcast进行管理。数据在集群中的所有Confluence节点上均匀分区,而不是在每个节点上复制。这允许更好的水平可扩展性,并且比完全复制的缓存需要更少的存储和处理能力。
由于这种缓存解决方案,为了最小化延迟,我们的节点应该位于相同的物理位置。
索引
Confluence索引的完整副本分别存储在每个Confluence节点上。索引同步服务使每个索引保持同步。
第一次设置集群时,将本地主目录(包括索引)从第一个节点复制到每个新节点。
将新Confluence节点添加到现有集群时,将现有节点的本地主目录复制到新节点。启动新节点时,Confluence将检查索引是否为当前索引,如果不是,则从共享主目录或正在运行的节点(具有匹配的内部版本号)请求索引的恢复快照,并在继续启动过程之前将其提取到索引目录中。如果无法生成快照或新节点未及时接收到快照,则将删除现有索引文件,Confluence将执行完整的重新索引。
如果Confluence节点与集群断开连接的时间很短(小时),则当其重新加入集群时,将能够使用日志服务更新其索引副本。如果一个节点宕机很长时间(天),其Lucene索引将变得过时,并且在节点启动过程中,它将从现有节点请求恢复快照。
如果怀疑所有节点上的索引都有问题,可以暂时禁用一个节点上的索引恢复,在该节点上重建索引,然后将新索引复制到每个剩余节点。
集群安全机制
Cluster Safety Job调度任务在Confluence中每30秒运行一次。在集群中,此作业仅在一个Confluence节点上运行。计划的任务以安全编号为基础进行操作,安全编号是一个随机生成的编号,存储在数据库和集群中使用的分布式缓存中。Cluster Safety Job将数据库中的值与缓存中的值进行比较,如果值不同,Confluence将关闭节点,这称为集群分割。此安全机制用于确保集群节点不会进入不一致状态。
如果集群发生分裂,则需要确保集群节点之间的网络连接正确。最有可能的是多播流量被阻止或未正确路由。
这种机制也存在于独立Confluence中。
平衡正常运行时间和数据完整性
通过更改集群安全调度作业的运行频率和Hazelcast心跳的持续时间(控制节点在从集群中删除之前失去通信的时间),可以微调集群中正常运行时间和数据完整性之间的平衡。在大多数情况下,默认值是合适的,但在某些情况下,例如,可能会决定牺牲数据完整性来增加正常运行时间。
数据完整性的正常运行时间
| Cluster safety job | Hazelcast heartbeat | 影响 |
|---|---|---|
| 1 minute | 1 minute | 可能会出现长达1分钟的网络中断或垃圾收集暂停,而不会触发集群死机。但是,如果两个节点不再通信,冲突数据可能会写入数据库长达1分钟,从而影响数据完整性 |
| 10 minutes | 30 seconds | 在没有将节点逐出集群的情况下,网络中断或垃圾收集暂停可能长达30秒。然后,在群集安全作业开始并关闭问题节点之前,被逐出的节点有多达10分钟的时间重新加入群集。虽然这可能会导致站点的正常运行时间延长,但冲突数据可能会写入数据库长达10分钟,从而影响数据的完整性 |
正常运行时间内的数据完整性
| Cluster safety job | Hazelcast heartbeat | 影响 |
|---|---|---|
| 15 seconds | 15 seconds | 网络中断或垃圾收集暂停超过15秒将触发群集死机。虽然这可能会导致站点的宕机时间延长,但节点之间的通信中断时间最多为15秒,因此只能向数据库写入数据,以确保更高的数据完整性 |
| 15 seconds | 1 minute | 在没有将节点逐出集群的情况下,网络可能会中断或垃圾收集暂停长达1分钟。一旦节点被逐出,它最多只能向数据库写入15秒,从而将对数据完整性的影响降至最低 |
可以通过修改 confluence.cluster.hazelcast.max.no.heartbeat.seconds 参数值 来修改心跳周期
群集锁和事件处理
如果操作只能在一个节点上运行,例如计划作业或发送每日电子邮件通知,Confluence使用集群锁确保操作仅在一个节点上执行。
类似地,一些操作需要在一个节点上执行,然后发布到其他节点。事件处理确保Confluence仅在提交并完成当前事务时发布集群事件。这是为了确保在接收和处理事件时,存储在数据库中的任何数据将可用于集群中的其他实例。事件广播仅针对某些事件进行,例如启用或禁用应用程序。
群集节点发现
配置群集节点时,可以提供每个群集节点的IP地址,也可以提供多播地址。
如果使用多播(需要网络支持):
Confluence将在多播网络地址上广播加入请求。Confluence必须能够在此多播地址上打开UDP端口,否则它将无法找到其他群集节点。一旦发现节点,每个节点都会以单播(正常)IP地址和端口进行响应,可以在其中联系节点进行缓存更新。Confluence必须能够打开UDP端口,以便与其他节点进行定期通信。
在第一个节点的设置过程中,可以从集群名称自动生成多播地址,也可以输入自己的多播地址。
基础设施和硬件要求
硬件和基础设施的选择取决于我们的平台使用量。以下是规划硬件和基础设施需求时需要考虑的一些方面。
群集节点
数据中心许可证不限制集群中的节点数。我们测试了多达4个节点的性能和稳定性。
虽然每个节点不需要完全相同,但为了保持一致的性能,我们建议它们尽可能接近。所有群集节点必须:
- 位于同一数据中心
- 运行相同的Confluence版本(对于Confluence节点)或相同的同步版本(对于同步节点)
- 具有相同的操作系统、Java和应用程序服务器版本
- 具有相同的内存配置(JVM和物理内存)(推荐)
- 使用相同的时区进行配置(并保持当前时间同步)。使用ntpd或类似服务是确保这一点的好方法。
(警告)您必须确保节点上的时钟不会发散,因为这可能会导致集群出现一系列问题。
内存要求
我们建议每个Confluence节点至少有10GB的RAM。大量并发用户意味着将消耗大量RAM。
以下是如何在不同大小的机器上分配内存的一些示例:
| RAM | 每一个节点 的要求 |
|---|---|
| 10GB |
|
| 16GB |
|
Confluence应用程序的最大堆(-Xmx)在setenv.sh或者setenv.bat中进行配置。数据中心的默认值应增加。我们建议保持最小(Xms)和最大(Xmx)堆的值相同。
外部进程池用于外部化内存密集型任务,以最小化对单个Confluence节点的影响。这些过程通过Confluence进行管理。每个进程(沙盒)(-Xmx)的最大堆和池中的进程数是使用系统属性设置的。在大多数情况下,默认设置就足够了,您不需要做任何事情。
独立同步群集节点
协作编辑需要同步。默认情况下,它由Confluence管理,但您可以选择在其自己的集群中运行同步。。
如果确实选择运行自己的同步群集,我们建议允许2GB内存用于独立同步。下面是一个如何在专用同步节点上分配内存的示例。
| Physical RAM | Breakdown for each Synchrony node |
|---|---|
4GB |
|
数据库
集群数据库最重要的要求是它有足够的可用连接来支持节点数量。
例如,如果:
- 每个Confluence节点的最大池大小为20个连接
- 每个同步节点的最大池大小为15个连接(默认值)
- 计划运行3个汇流节点和3个同步节点
数据库服务器必须允许至少105个到Confluence数据库的连接。实际上,出于调试或管理目的,您可能需要超过最低要求。
还应该确保目标数据库列在当前支持的平台中。一般集群解决方案的负载高于独立安装,因此使用受支持的数据库至关重要。
共享主目录和存储要求
所有Confluence群集节点必须能够访问同一路径中的共享目录。支持将NFS和SMB/CIFS共享作为共享目录的位置。由于此目录将包含大量数据(包括附件和备份),因此它的大小应该足够大,并且我们应该制定一个计划,在需要时如何增加可用磁盘空间
记住我和会话超时
默认情况下,“记住我”选项在集群中强制执行。用户不会在登录页面上看到“记住我”复选框,他们的会话将在节点之间共享。
负载平衡器
我们建议使用您最熟悉的负载平衡器。负载平衡器需要支持“session affinity”和WebSocket。这是Confluence和同步所必需的。如果我们是在AWS上部署,则需要使用应用程序负载平衡器(ALB)。
以下是配置负载平衡器时的一些建议:
在负载平衡器上排队请求。通过确保提供给节点的最大请求数不超过Tomcat可以接受的http线程总数,可以避免节点无法处理的请求过多。我们可以在安装目录下的/conf/server.xml中找到检查maxThreads的配置项。
不要在其他节点上重播失败的幂等请求,因为这会很快将问题传播到所有节点。
使用最少连接作为负载平衡方法,而不是循环,可以在节点加入集群或移除后重新加入时更好地平衡负载。
网络适配器
使用单独的网络适配器进行服务器之间的通信。群集节点应具有用于服务器间通信的单独物理网络(即单独NIC)。这是使集群快速可靠运行的最佳方法。如果您通过具有大量其他数据流的网络连接群集节点,则可能会出现性能问题
https://confluence.atlassian.com/conf71/confluence-data-center-technical-overview-979424260.html