高可用性
Data Center利用数据中心主动集群和自动热故障转移,实现高 可用性。集群多活服务器可确保在出现硬件故障时,用户可以不 间断访问关键Atlassian应用程序。如果出现节点故障,负载均衡 器自动将用户重定向到池或集群中其他主动节点上。 这一过程自动完成,用户基本上不会察觉到任何停机迹象。集成 业界技术标准的负载均衡、数据库集群与共享文件系统,将单点 故障降至最低。
我们知道,不能因为维护而停下手头的工作,而对于许多组织 来说,管理员很难安排合适的维护时间。毕竟,核心任务型应 用停止的话会影响生产力和团队输出。
通过集群多台服务器实现零停机升级(Jira Software和Jira Service Desk),解决了意外停机问题,但升级软件等计划停机呢?我们知道,许多管理员会安排周末升级,避免生产力中断,但我们相信还有更好的办法,无需占用管理员晚上和周末的时间。
假设,您有一个三个节点的数据中心集群,运行Jira Software,现在准备升级到最新版本。要使每个节点都升级到最新版本,一次只能升级一个节点,而且需要关停节点。此时,所有用户流量需要重定向到其他两个在线节点,以便用户可以照常工作。所有节点都升级完毕后,可以应用数据库架构更改。

零停机升级可以在不中断最终用户工作的情况下管理整个升级过程。这样可以更加自信地频繁升级,更快地获取最新和更好 的特性和修复。
只读模式(Confluence)
Confluence Data Center提供了只读模式,允许用户继续工作,而管理员可以一边执行一系列维护活动。启动只读模式之后,您可以一边执行维护工作,而不会干扰用户继续使用内容。用户可以查看、搜索和导航页面、博客和附件,但不能编辑。只读模式下,管理操作不受限制,如管理应用或更改站点配置等。您可以先启用只读模式,然后再升级Confluence Data Center实例,合并实例,迁移到新平台或者执行其他维护工作,同时用户仍然可以访问Confluence内容。
作为管理员,您可以在管理控制台的维护页面打开和关闭只读模 式。此页面还显示了哪些用户安装了与只读模式兼容的应用。如果 应用不兼容只读模式,可能需要暂时禁用,防止用户创建或修改内容。
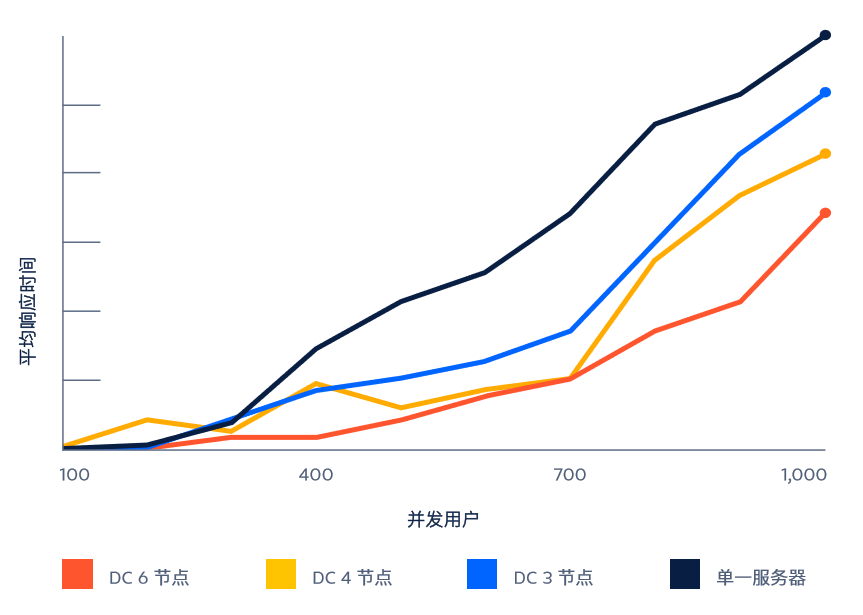
规模性能
Data Center集群的每个节点都可以为并发用户增长容量,因此,在扩展Atlassian应用程序时不会牺牲性能。在集群中指定专 门用于自动化任务的节点,或将特定类型团队的流量或API流量路 由到特定节点,同时将剩余流量定向到其他节点,以提供最高质 量的服务。
项目归档(Jira Data Center)
团队每天依靠Jira Software来完成工作,因此,保持Jira良好的性 能和可读性至关重要。随着组织中Jira的使用范围不断扩大,制定 计划如何删除过时信息就显得越来越重要。因此,我们为Jira Data Center引入了项目归档。现在,您可以创建更多空间,为仍 然相关的数据释放资源,从而提升Jira的性能和可读性。我们对拥 有一百万个问题的Jira Software实例进行性能测试,归档了50% 项目和问题,观察到Jira面板加载速度提高了11%,JQL搜索速度 快了25%。总的来说,我们看到Jira的性能随着归档信息量线性增加。
客户故事: Cerner Corporation
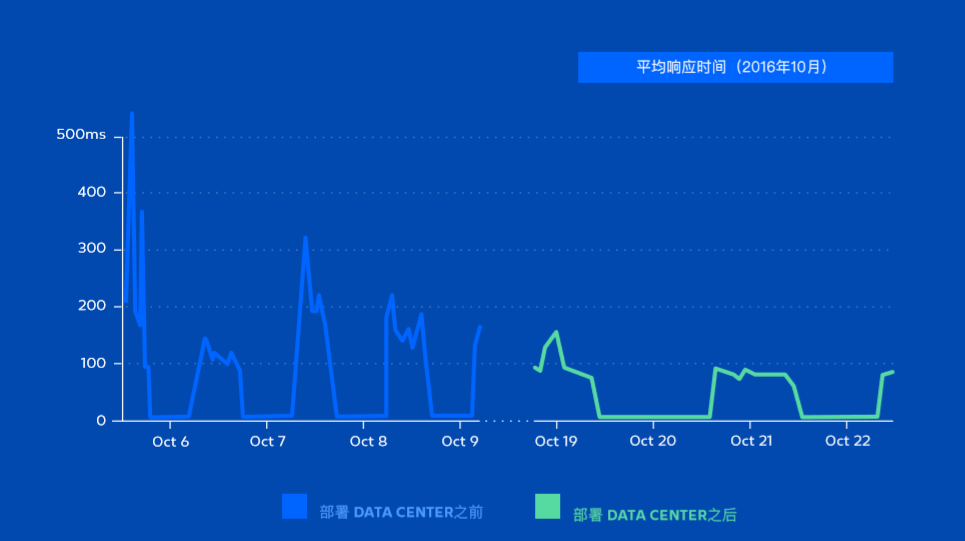
Cerner Corporation通过将外部REST API请求智能分发到专用节点,大大缩短了应用程序响应时间。在部署Data Center第一周,REST API节点流量是其他两个节点的4倍。与单一服务器实例相比,响应时间更快,非管理节点的CPU使用率降低, 并且在将Jira Software扩展到数千个新用户之后,2016年没有出现一次意外中断。
Cerner需要确保在继续增加用户的同时维持或改善应用程序响应时间。这样的架构 证明,Cerner可以将响应时间缩短近一半 - 从150秒减少到80秒。即使在峰值流量 期间,特别是在加载页面时,也能保持稳定的响应时间。
即时扩展
轻松地向Data Center集群添加新节点,无需停机或中断服务。集 群现有节点自动同步新成员索引和插件,从而实现无障碍部署,并 确保最大程度的正常运行时间。
由于Data Center是按用户数量授权的,因此您可以更好地预测成本 并扩展环境,无需为新服务器或CPU支付额外的许可费用。
身份验证和控制
随着我们的产品对您的用户而言变得更加关键,您需要着眼于标准 化,控制最终用户访问和使用这些系统的方式。对于访问控制, Data Center支持SAML 2.0,可以使用现有的身份验证提供商进行 身份验证。
不仅简化并帮助确保遵守公司的安全政策,而且用户不必记住(或 忘记)多个密码。
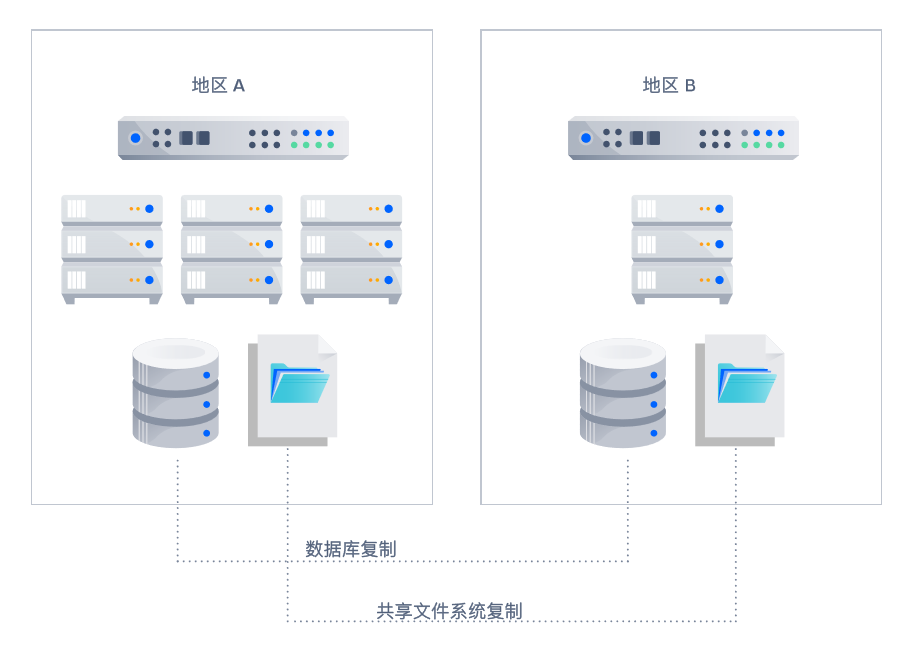
灾难恢复
Atlassian Data Center拥有“冷备”灾难恢复站点,供系统完全中断时使用。灾难恢复站点与生产站点分开,并且仅在需要时才启动。 在将数据库和共享文件系统从生产站点同步复制到灾难恢复站点 时,您可以根据需要实施最适合的流程。
虽然您可能已针对当前的Atlassian环境制定了灾难恢复计划,但是有了Data Center,除了复制数据库和共享存储文件夹之外,还可以使用DR备份从生产实例共享应用程序索引。因此,在需要故障转移的时候,有了这些索引,就可以显著缩短DR备份的启动时间。如果发生灾难,可以将用户重定向到DR系统并立即恢复上线。只需轻轻按下开关,就可以恢复。
Bitbucket Data Center 智能镜像
Bitbucket Data Center 智能镜像提供就近服务器使用的代码库,大大缩短了克隆时间 - 从数小时缩短到数分钟。
许多使用Git的软件开发团队由于存储了大量历史信息,使用单一代 码库或存储了大型二进制文件(或以上三种情形均有),使得代码 库极为庞大。拥有分布式软件开发团队的公司基本上无法控制站点 之间的网络性能。综合起来,开发者需要等待漫长的时间(通常是 数小时),克隆位于全球各地的大型代码库,浪费了宝贵的开发时 间。
智能镜像能设置远程代码库的实时镜像只读副本节点,帮助您夺回 浪费的开发时间。镜像自动同步其托管的所有代码库和Bitbucket Data Center主实例。远程用户可以从镜像中克隆和获取代码库,更 快地获得相同的内容。可以将镜像配置为镜像Bitbucket主要实例中 全部项目的所有代码库,或者只镜像管理员配置的部分项目。
在Atlassian,我们看到使用智能镜像之后,在旧金山和悉尼克隆 5GB的代码库比之前快了25倍

价格
可参见:https://www.atlassian.com/licensing/future-pricing/data-center-pricing/pricing-tables
1 Comment
红旗公
https://confluence.atlassian.com/adminjiraserver072/jira-performance-metrics-839981964.html